A korábbi útmutatókban teljes mértékben belépettünk a CQL-be és a Cassandra kezelésének elősegítésébe, láttuk a Cassandra billentyűparancsok és táblázatok alapvető műveleteit, képesek voltunk ezeket alkalmazni egy kezdeti struktúra létrehozására az adatbázisban, Jelentős mennyiségű fejlett koncepció van azonban, amelyeket tudnunk kell, hogy a legtöbbet hozhassuk ki a Cassandrából.
Ezek a fogalmak vagy jellemző, hogy valamilyen módon meghívjuk őket, lehetővé teszik számunkra, hogy különböző funkciókat érjünk el tábláinkban, és sokkal nagyobb lehetőségeket biztosítsanak nekünk, mint a többi NoSQL adatbázis .
Adattípusok
Korábban készítettünk néhány táblát, és olyan értékeket használtunk, mint például a szöveg vagy a dátum az oszlopokhoz, de ez még nem minden, ami a CQL rendelkezésére áll, nézzük meg, hogy milyen típusú adatok vannak a műveletekhez:
ascii
Karakterlánc US-ASCII típusú.
bigint
Az egész érték 64 bit hosszú.
folt
Az adattípus hexadecimálisan kifejezve a CQL parancskonzolon, ezen felül nincs érvényesítés és tetszőleges bájtokon alapul.
logikai
A klasszikus típusú logikai adatok, ahol az értékek lehetnek igazak vagy hamisak.
pult
A számláló új típusú adatok azok számára, akik a relációs világból származnak, és azt jelzi, hogy 64 bites eloszlású.
decimális
Egy másik adattípus, amelyet felismerhetünk, és amely decimális pontosságot biztosít számunkra.
kettős
Lebegőpontos adatok típusa, de 64 bitre alapozva.
úszó
Az előzőhöz hasonlóan ez egy típusú lebegőpontos adat, de 32 bites alapú.
inet
Ez a típus nagyon különleges és ugyanakkor nagyon hasznos, és lehetővé teszi számunkra egy IP-cím karakterláncának tárolását, támogatja az IPV4 és az IPV6 formátumot is.
int
A klasszikus egész számú adat, amely legfeljebb 32 bit számot támogat.
lista
Egy másik típusú adat, amely debütál a Cassandra-ban, és lehetővé teszi számunkra az elemek rendezett gyűjteményének tárolását.
térkép
A listához hasonlóan új típusú adatok is vannak, és lehetővé teszi egy asszociatív tömb tárolását, ami nagyon hasznos az alkalmazások fejlesztésében.
készlet
Az adatlista típusához hasonlóan elemgyűjteményt tárol, de külön megrendelés nélkül.
szöveg
Tároljon egy kódolt karakterláncot.
időbélyeg
A dátumot és az időt tároló adattípus, 8 bájtos egész számként kódolva.
varint
Tetszőleges egész számok precíziós adatainak típusa.
Mint látjuk, számos típusú adat felismerhető, ha a relációs világból származunk, mint mások, amelyeket először látunk, és amelyek kitűnnek a Cassandrától az egyéb adatbázisoktól.
Táblázat tulajdonságai
A Cassandra-ban nemcsak adattípusok vannak a táblázatokhoz, a CQL-nek köszönhetően az Adatbázis tulajdonságainkon belül hozzárendelhetjük a táblázatokat, amelyek nagyban segítenek a karbantartási és fejlesztési feladatokban. Nézzük meg, mi áll rendelkezésre.
gyorsítótárral
Ez a tulajdonság lehetővé teszi a gyorsítótár memória optimalizálását. Az ehhez a tulajdonsághoz rendelkezésre álló szintek mindegyike vagy mind, csak kulcsok vagy csak kulcsok, sorok_csak vagy csak sorok és nincs, vagy nincs. Az összes lehetőség nagyon hasznos, azonban a row_only- t csak óvatosan kell használni, mivel a Cassandra jelentős mennyiségű adatot helyez a memóriába, amikor ezt az opciót használja.
megjegyzés
Opció, amely jelen van a relációs modellben, és amelyet az adminisztrátorok vagy a fejlesztők használnak jegyzetek készítéséhez és a táblázatokban szereplő fontos részletek kiemeléséhez.
Tömörítő
Ez a tulajdonság lehetővé teszi a forgácsolók kezelésének stratégiájának meghatározását, ezek lehetnek típusúak: Az első SizeTiered, amelyet akkor indítunk el, amikor az asztal átlép egy korlátozást, ennek a stratégiának az előnye, hogy nem rontja az írási teljesítményt, azonban Egy hátránya, hogy alkalmanként kétszer akkora méretű adatot használ a lemezen, ami rossz olvasási teljesítményt eredményez. A második stratégia a LeveledCompaction, és idővel különböző szinteken működik, összekapcsolva a táblákat a hosszabbokkal, ami meglehetősen jó olvasási teljesítményt eredményez.
összenyomás
Ez a tulajdonság határozza meg az információk tömörítésének módját. Kiválaszthatjuk, hogy a teljesítményt elérjük-e sebességben vagy térben, ahol nagyobb sebesség, kevesebb lemezterület kerül megtakarításra.
Gc_grace_seconds
Ez a tulajdonság meghatározza a várakozási időt az információk eltávolításához a sírkövekből. Alapértelmezés szerint 10 nap.
Populate_io_cache_on_flush
Ez a tulajdonság alapértelmezés szerint le van tiltva, és csak akkor kell aktiválnunk, ha azt várjuk, hogy az összes információ belefér a gyorsítótár memóriájába.
Read_repair_chance
Nagyon érdekes tulajdonság, amely 0 és 1, 0 közötti számot jelöl, meghatározva az információ helyrehozásának valószínűségét, ha a kvórum nem érhető el. Az alapértelmezett érték 0, 1.
Replicate_on_write
Ez a tulajdonság csak a számlálótáblákra vonatkozik. A definiálás után a replikák az összes érintett replikára írnak, figyelmen kívül hagyva a megadott konzisztenciaszintet.
Akkor már tudjuk, hogy mi van, mind az adattípusok, mind a tulajdonságok szintjén, itt az ideje, hogy a megtanult dolgok egy részét alkalmazzuk a Cassandra- táblázatainkon.
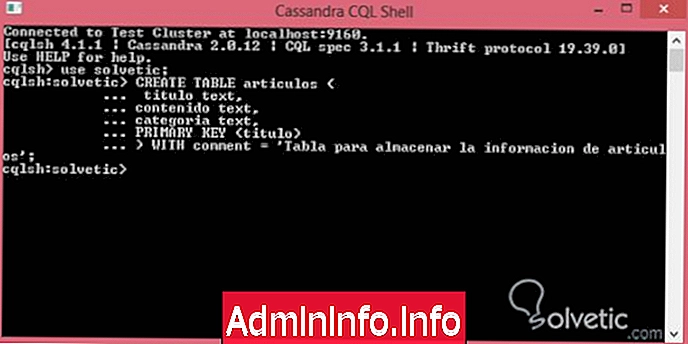
Először létrehozunk egy egyszerű táblát, amelyre alkalmazni fogjuk a megjegyzések tulajdonságot, nézzük meg a szintaxist, amelyet ehhez használunk:
Táblázat létrehozása (szöveg címe, szöveges tartalom, szövegkategória, ELSŐ KULCS (cím)) WITH comment = 'Táblázat a cikk adatainak tárolására';Megnyitjuk a CQL parancskonzolt, és létrehozjuk a táblázatot az említett tulajdonsággal, nézzük meg, hogy néz ki:

Mint tudjuk, a parancskonzol nem ad vissza semmit, kivéve, hogy nincs hiba, de ha meg akarjuk nézni ezeket a változásokat, akkor felkereshetjük OpsCenterünket és ellenőrizhetjük, hogy minden helyesen ment-e:
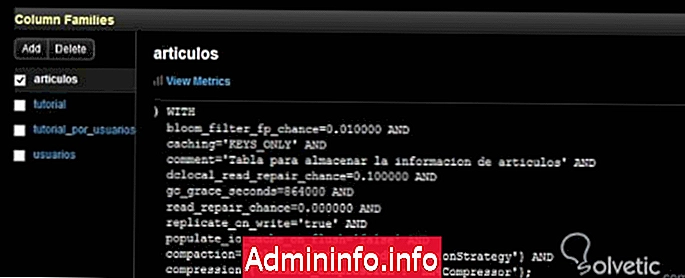
Amint látjuk, láthatjuk megjegyzésünket és más tulajdonságainkat az alapértelmezett értékükkel. Fontos megemlíteni, hogy a Cassandra többi tulajdonságának meghatározása meglehetősen egyszerű, amint azt az előző példában láthattuk, a WITH szintaxissal minden probléma nélkül meg tudjuk csinálni.
Tömörítés és tömörítés
Készítünk egy másik példát, ahol meghatározni fogjuk a tömörítési és tömörítési tulajdonságokat, de ehhez fontos tudni, hogy ezeknek al-lehetőségeik vannak soruk a felhasználásukhoz, nézzük meg a tömörítést, amelyet tudnunk kell:
Sstable_compression
Ez az opció határozza meg a használni kívánt tömörítési algoritmust, értékei: LY4Compressor, SnappyCompressor és DeflateCompressor .
Chunck_length_kb
A táblákat tömbök tömörítik. A hosszabb értékek általában jobb tömörítést biztosítanak, de növelik az olvasáshoz szükséges információk méretét. Alapértelmezés szerint ez az opció 64 kb-ra van állítva.
A tömörítési lehetőségek manipulálása jelentős teljesítménynövekedést eredményezhet, többek között a Cassandra implementációinak alapértelmezett értékeivel, de tökéletesítésük érdekében ezeket az értékeket kell használni. Lássuk most, mit tudnunk kell a tömörítéshez:
Bekapcsolt
Határozza meg, hogy a tulajdonság fut-e a táblázatban, bár alapértelmezés szerint az összes tulajdonság engedélyezte a tömörítést .
osztály
Itt meghatározzuk a táblázatok kezelésének stratégiáját.
min_threshold
Ez az érték a SizeTiered stratégiával érhető el, és képviseli a tömörítési folyamat elindításához szükséges minimális táblázatok számát. Alapértelmezés szerint a 4-ben van megadva.
max_threshold
Ugyanígy érhető el a SizeTiered stratégiában, és meghatározza a tömörítés során feldolgozott táblák maximális számát. Alapértelmezés szerint van meghatározva 32-ben.
Ezek a tulajdonságok legfontosabb lehetőségei közül néhány, fontos megemlíteni, hogy ezen opciók meghatározásához JSON szintaxist kell használnunk, hogy érvényes legyen, tehát lássunk példát e két tulajdonság beillesztésére:
CREATE TABLE tulajdonságok_tábla (int id, szöveg neve, szöveg tulajdonsága, varint száma, PRIMARY KEY (id)) WITHcompression = {'stabil_compression': 'DeflateCompressor', 'chunk_length_kb': 64} ANDcompaction = {'class': 'SizeTieredCompactionStrategy', 'min_küszöb': 6}; Mint láthatjuk, megváltoztattuk a tömörítés típusát, és meghatároztuk annak méretét, emellett a tömörítéshez a szokásos stratégiát az osztályértékkel hagytuk, és a min_küszöböt 6-ra definiáltuk, ezáltal növelve az alapértelmezett értéket, hogy befejezzük, nézzük meg, hogy mikor néz ki ez A parancskonzolon futtatjuk: $config[ads_text5] not found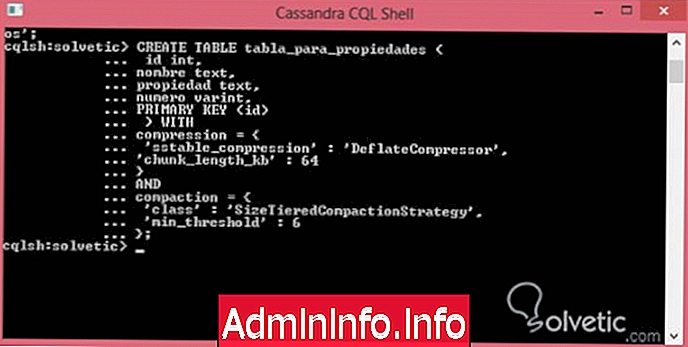
Az adatok rendezése a fürtben
Az utolsó oktatóprogramban láthattuk, hogy egynél több elsődleges kulcs meghatározását követően csoportosító kulcsként jönnek létre, és jelzik, hogy a Cassandra hogyan rendeli az információkat, alapértelmezés szerint a sorrend növekvő sorrendben van meghatározva, és lekérdezés csökkenő sorrendben készül. Ez teljesítményproblémákat okozhat nekünk, azonban a Cassandra megoldást kínál minden problémára, és ez a CLUSTERING ***** BY nyilatkozattal történik . Lássuk, hogyan kell használni.
CREATE TABLE rendezett felhasználók (felhasználói szöveg, időbélyegzés dátuma, úszó fizetés, szöveges osztály, felügyeleti szöveg, PRIMÁRIS KULCS (felhasználó, dátum)) CLUSTERING ***** BY (DESC dátum);Futtassuk a szintaxist a parancskonzolon, és nézzük meg, hogy néz ki:
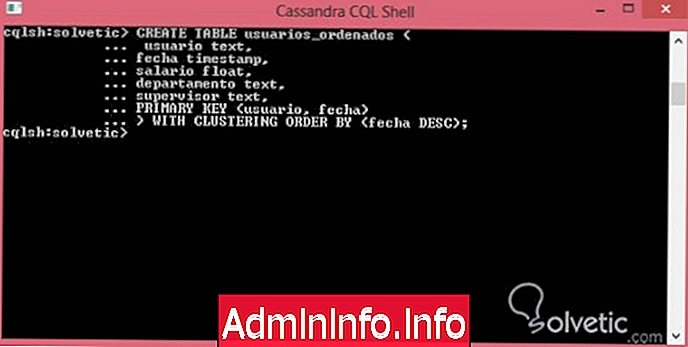
Mint láthattuk, meglehetősen egyszerű volt ezt a problémát egy egyszerű vonallal megoldani, de a legfontosabb dolog az, hogy kibővítettük tudásunkat a Cassandra tábláinak kezelésével kapcsolatban, amely ezzel az oktatóanyaggal zárult le, ahol mindent lefedtünk, Tudnunk kell a táblák optimális létrehozásának Cassandrában .
Cikk